

파이토치(PyTorch)를 사용하여 인공 신경망(Deep Neural Network, DNN)을 구현하고,
심장병 데이터셋으로 모델을 학습한 후 평가하는 내용
Heart Disease Predictions
https://www.kaggle.com/code/desalegngeb/heart-disease-predictions


scikit-learn 설치
seaborn 설치
필요한 라이브러리 및 설정
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from time import time
import torch
from torch import nn
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score- Pandas: 데이터 프레임을 처리하기 위한 라이브러리.
- Matplotlib, Seaborn: 데이터 시각화를 위한 라이브러리.
- Torch: 파이토치를 사용하여 신경망을 구축.
- Scikit-learn: 데이터 전처리 및 학습, 테스트 데이터셋 분리.
- F1 Score: 모델 성능 평가를 위한 F1 점수 계산.
하이퍼파라미터 설정
INPUT_DIM = 13
MY_HIDDEN = 1000
MY_EPOCH = 1000- INPUT_DIM: 입력 데이터 차원 수(13).
- MY_HIDDEN: 은닉층의 뉴런 수(1000).
- MY_EPOCH: 학습 에포크 수(1000).
데이터 준비 및 전처리
raw = pd.read_csv('./dnn/heart.csv')
raw = raw.sample(frac=1).reset_index(drop=True)
raw = raw.drop(raw.index[100:])- 데이터 불러오기: Kaggle에서 제공하는 심장병 데이터셋을 불러옵니다.
- 데이터 섞기: 데이터 순서에 의한 영향을 없애기 위해 섞습니다.
- 데이터 줄이기: 303개 데이터 중에서 100개만 사용합니다.
X_data = raw.drop('target', axis=1)
Y_data = raw['target']- X_data: 타겟(target)을 제외한 입력 데이터.
- Y_data: 타겟(target) 데이터.
X_train, X_test, Y_train, Y_test = train_test_split(X_data, Y_data, test_size=0.3) # 학습용/테스트용 데이터 분리- train_test_split: 데이터를 학습용과 테스트용으로 70:30 비율로 나눕니다.
# 데이터 준비
# https://www.kaggle.com/code/mragpavank/heart-disease-uci/input
raw = pd.read_csv('./dnn/heart.csv')
# pandas의 dataframe을 섞는다.
# raw = raw.sample(frac=1)
# pandas의 dataframe을 섞은 후 인덱스 재조정.
raw = raw.sample(frac=1).reset_index(drop=True)
# 303개의 행중에서 100개만 가져 올 때 =>
# 100개의 행에는 target이 True인것만 있음 그래서, 위에 처럼 섞어야 함.
# raw.drop(raw.index[100:], inplace=True)
raw = raw.drop(raw.index[100:])
# 데이터 원본 출력, 전체 행의 수 : 303개, 전체 열의 수 : 14(target 포함)
print('원본 데이터 샘플 10개')
print(raw.head(10))
print('원본 데이터 통계')
print(raw.describe())

주어진 데이터셋에서 타겟 열을 분리하고,
입력과 출력 데이터를 학습용과 테스트용으로 나누는 기본적인 데이터 처리 과정
특성 이름 확인
# 데이터를 입력과 출력으로 분리
X_data = raw.drop('target', axis=1)
Y_data = raw['target']
names = X_data.columns
print(names)
# 전처리 작업 : 훈련 전 이상 데이터를 줄여서 적합하고 유의미한 자료로 만드는 과정
# INPUT_DIM의 값도 조정해야 함. 예) 13 -> 11
# X_data.drop('fbs', axis=1, inplace=True)
# X_data.drop('chol', axis=1, inplace=True)'fbs'나 'chol' 열을 제거할 때, 데이터 차원(INPUT_DIM)이 13에서 11로 줄어들 수 있습니다.
X_data.drop('fbs', axis=1, inplace=True): 'fbs' 열을 삭제하여 X_data에서 해당 변수를 제거할 수 있습니다.
inplace=True는 원본 데이터를 직접 수정한다는 뜻입니다.
INPUT_DIM은 신경망의 입력 차원에 영향을 미치므로, 열을 제거하면 이에 맞게 변경해야 합니다.
학습 데이터와 테스트 데이터 분리
# 데이터를 train(훈련용, 학습용)과 test(평가용)으로 분리
X_train, X_test, Y_train, Y_test = \
train_test_split(X_data, Y_data, test_size=0.3)
# shape 출력
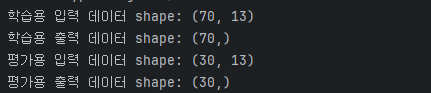
print('학습용 입력 데이터 shape:', X_train.shape)
print('학습용 출력 데이터 shape:', Y_train.shape)
print('평가용 입력 데이터 shape:', X_test.shape)
print('평가용 출력 데이터 shape:', Y_test.shape)X_train.shape: 학습용 입력 데이터의 차원(행과 열의 수)을 출력합니다.
예를 들어, (70, 13)이라면 70개의 데이터가 있고 각 데이터는 13개의 특성을 가지고 있다는 의미입니다.
Y_train.shape: 학습용 타겟 데이터의 차원을 출력합니다.
예를 들어, (70,)이라면 70개의 타겟 값(레이블)이 있다는 뜻입니다.
X_test.shape: 테스트용 입력 데이터의 차원을 출력합니다.
예를 들어, (30, 13)이라면 30개의 데이터가 있고 각 데이터는 13개의 특성을 가지고 있습니다.
Y_test.shape: 테스트용 타겟 데이터의 차원을 출력합니다.
예를 들어, (30,)이라면 30개의 타겟 값이 있다는 의미입니다.
# 입력 데이터 z-점수 정규화
# 결과가 numpy의 n-차원 행렬 형식
scaler = StandardScaler() # z-점수 정규화
# scaler = MinMaxScaler() # 최소-최대 정규화
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)
# print('Before type:', type(X_train))
# numpy에서 pandas 로 변경
# header 정보 복구 필요
X_train = pd.DataFrame(X_train, columns=names)
X_test = pd.DataFrame(X_test, columns=names)
# print('After type:', type(X_train))
print('z-점수 정규화 된 학습용 데이터 샘플 10개')
print(X_train.head(10))
print('z-점수 정규화된 데이터의 통계 출력')
print(X_train.describe())
sns.set(font_scale=2)
sns.boxplot(data=X_train, palette="colorblind")
plt.show()이 코드는 입력 데이터의 Z-점수 정규화를 수행한 후,
정규화된 데이터를 시각화하는 작업을 진행하고 있습니다
Z-점수 정규화 (StandardScaler)
scaler = StandardScaler() # Z-점수 정규화를 위한 StandardScaler 객체 생성
X_train = scaler.fit_transform(X_train) # 학습 데이터에 대해 정규화 적용
X_test = scaler.fit_transform(X_test) # 테스트 데이터에 대해 정규화 적용- StandardScaler(): 데이터를 평균이 0, 표준편차가 1인 분포로 변환하는 Z-점수 정규화(Z-score normalization)를 적용합니다. 이 방법은 데이터의 각 값에서 평균을 빼고 표준편차로 나누어, 특성 값들이 정규 분포에 가깝게 만들어줍니다.
scaler.fit_transform(X_train): 학습 데이터X_train에 대해 정규화를 적용하며, fit으로 평균과 표준편차를 계산하고, transform으로 데이터를 변환합니다.- 정규화의 이유: 신경망에서 입력 데이터의 스케일이 너무 크거나 작은 경우 학습이 제대로 이루어지지 않을 수 있기 때문에, 데이터의 스케일을 동일하게 맞추는 것이 중요합니다.
Numpy 배열을 Pandas DataFrame으로 변환
X_train = pd.DataFrame(X_train, columns=names) # 정규화된 데이터를 DataFrame으로 변환 (columns=names로 열 이름 복원)
X_test = pd.DataFrame(X_test, columns=names) # 동일하게 테스트 데이터도 변환fit_transform()을 통해 정규화된 데이터는 numpy 배열 형태로 반환됩니다. 이를 다시 Pandas DataFrame 형태로 변환하여 열 이름을 복구합니다.pd.DataFrame(X_train, columns=names): DataFrame으로 변환할 때,columns=names를 사용하여 원본 데이터의 열 이름을 다시 설정합니다.
정규화된 데이터 출력
print('z-점수 정규화 된 학습용 데이터 샘플 10개')
print(X_train.head(10)) # 정규화된 학습용 데이터에서 첫 10개 샘플 출력
print('z-점수 정규화된 데이터의 통계 출력')
print(X_train.describe()) # 정규화된 데이터의 통계량 출력 (평균, 표준편차 등)- 샘플 출력 (
head()): 정규화된 학습 데이터에서 첫 10개의 샘플을 출력합니다. 이때 각 특성(feature)이 평균이 0에 가깝고, 표준편차가 1에 가깝도록 변환된 것을 확인할 수 있습니다. - 통계량 출력 (
describe()): 정규화된 데이터에 대한 통계량을 출력합니다.describe()는 평균, 표준편차, 최소값, 최대값 등의 통계 정보를 제공합니다. 여기서 각 특성의 평균이 0, 표준편차가 1에 가깝다는 것을 확인할 수 있습니다.
데이터 시각화
sns.set(font_scale=2) # Seaborn 스타일 설정 (글자 크기 크게 조정)
sns.boxplot(data=X_train, palette="colorblind") # 정규화된 학습 데이터에 대한 상자 그림 출력
plt.show() # 상자 그림을 화면에 표시- Seaborn 설정:
sns.set(font_scale=2)는 시각화에서 글자의 크기를 크게 조정하는 설정입니다. 그래프에서 텍스트가 더 잘 보이도록 하기 위함입니다. - 상자 그림 (Boxplot):
sns.boxplot()을 사용해 정규화된 데이터에 대한 상자 그림(Boxplot)을 그립니다. 각 특성(feature)에 대해 데이터 분포를 시각화하는데, 상자 그림은 데이터의 최소, 1사분위수, 중앙값, 3사분위수, 최대값을 보여줍니다.- 상자 그림을 통해 데이터의 이상치를 시각적으로 확인할 수 있으며, 데이터가 정규화된 후의 분포가 어떻게 되는지를 직관적으로 파악할 수 있습니다

인공 신경망 구성
nn.Sequential()로 신경망을 정의하고, 3개의 선형 계층 (nn.Linear())과 2개의 Tanh 활성화 함수, 그리고 출력층에 Sigmoid 함수를 사용합니다. 첫 번째 은닉층은 입력 데이터를 1000개의 뉴런에 연결하고, 두 번째 은닉층 역시 1000개의 뉴런을 가집니다. 최종적으로 출력층은 하나의 값(이진 분류)을 출력합니다.
print("{0:=^20}".format('인공 신경망 구현'))
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN), # 첫 번째 은닉층
nn.Tanh(), # 활성화 함수 (Tanh)
nn.Linear(MY_HIDDEN, MY_HIDDEN), # 두 번째 은닉층
nn.Tanh(), # 활성화 함수 (Tanh)
nn.Linear(MY_HIDDEN, 1), # 출력층
nn.Sigmoid() # 활성화 함수 (Sigmoid)
)
print('DNN 요약')
print(model)
- Sequential 모델: 파이토치에서 계층을 순서대로 쌓아 신경망을 만듭니다.
- 첫 번째 Linear 계층: 입력층(13차원)과 은닉층(1000 뉴런) 연결.
- 두 번째 Tanh: 은닉층에 비선형성을 추가하는 활성화 함수.
- 두 번째 Linear: 은닉층과 출력층(1 뉴런) 연결.
- 마지막 Sigmoid: 이진 분류를 위한 활성화 함수.
모델 학습
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # SGD 최적화 기법
criterion = nn.MSELoss() # 손실 함수 (평균 제곱 오차)
X_train = torch.tensor(X_train.values).float() # 학습 데이터를 Tensor로 변환
Y_train = torch.tensor(Y_train.values).float()
for epoch in range(MY_EPOCH): # 1000번 반복
output = model(X_train) # 모델에 학습 데이터 입력
output = torch.squeeze(output) # 출력값의 차원 줄이기
loss = criterion(output, Y_train) # 손실 계산
if(epoch % 10 == 0): # 10번마다 손실값 출력
print('Epoch: {:3},'.format(epoch), 'Loss: {:.3f}'.format(loss.item()))
optimizer.zero_grad() # 기울기 초기화
loss.backward() # 역전파
optimizer.step() # 가중치 업데이트- Optimizer(SGD): 경사 하강법(Stochastic Gradient Descent)을 사용해 가중치 업데이트.
- Criterion(MSELoss): 손실 함수로 평균 제곱 오차(MSE)를 사용.
- Epoch 반복: 1000번 반복하면서 모델을 학습. 매 10번째 에포크마다 손실값 출력.
총 파라미터 수 계산
total = sum(p.numel() for p in model.parameters())
print('총 파라미터 수 : {:,}'.format(total))- model.parameters(): PyTorch 신경망 모델에서 학습 가능한 모든 파라미터(가중치와 편향)를 반환합니다. 이 함수는 신경망에서 사용된 모든 레이어의 파라미터를 iterable 형태로 제공해 줍니다.
- p.numel(): 파라미터 텐서의 **전체 원소 개수(텐서 크기)**를 반환합니다. 예를 들어, 1000개의 뉴런을 가진 레이어라면 해당 레이어의 가중치 파라미터 개수를 계산할 수 있습니다.
- sum(): 모든 레이어의 파라미터 개수를 더해 신경망 전체의 총 파라미터 수를 계산합니다.
- 결과 출력: 총 파라미터 수를 세 자리마다 쉼표(,)를 넣어서 보기 쉽게 출력합니다. (format(total))
예를 들어, 입력층이 13개이고 두 개의 은닉층에 각각 1000개의 뉴런이 있다면, 수천 개에서 수백만 개의 파라미터가 포함될 수 있습니다. 이 파라미터들은 모델 학습 중에 업데이트됩니다.
최적화 기법과 손실 함수 설정
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# RMSprop은 최적화 도중, 학습률을 상황에 맞게 조절하는 기술을 추가한 알고리즘
# optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = nn.MSELoss()- optimizer: 모델의 파라미터를 학습시키기 위해 최적화 알고리즘을 설정합니다.
- SGD (Stochastic Gradient Descent): 확률적 경사 하강법을 사용하여, 주어진 학습률(lr=0.01)에 따라 가중치들을 업데이트합니다. 학습률(lr)은 가중치 업데이트 크기를 결정하는 중요한 하이퍼파라미터입니다.
- 다른 옵션들:
- RMSprop: 학습률을 자동으로 조정하며, 수렴 속도를 높일 수 있는 기법입니다. 주석 처리된 코드로 제공되고 있습니다.
- Adam: RMSprop과 모멘텀을 결합한 알고리즘으로, 파라미터 업데이트에 있어 매우 효율적인 알고리즘입니다. 역시 주석으로 제공됩니다.
- criterion: 손실 함수로 **MSE (Mean Squared Error)**를 설정합니다.
- MSELoss(): 평균 제곱 오차를 계산하는 손실 함수로, 신경망의 예측값과 실제 타겟 값 간의 차이를 제곱하여 평균낸 값을 반환합니다. 이 값을 최소화하는 것이 목표입니다.
- MSE는 주로 회귀 문제에서 사용되지만, 이 코드에서는 이진 분류를 위해 MSE를 사용하고 있습니다. 다른 분류 문제에서는 Binary Cross-Entropy가 자주 사용되지만, 여기서는 MSE를 선택한 것 같습니다.
데이터 변환
X_train = torch.tensor(X_train.values).float()
Y_train = torch.tensor(Y_train.values).float()- torch.tensor(): Pandas DataFrame 형태의 학습 데이터를 PyTorch Tensor 형태로 변환합니다. PyTorch는 텐서 연산을 통해 모델 학습이 이루어지므로, 데이터를 텐서로 변환하는 것이 필수적입니다.
- X_train.values: Pandas DataFrame을 Numpy 배열로 변환하는 속성. 이를 통해 X_train의 값들만 가져옵니다.
- .float(): 변환된 텐서의 데이터 타입을 32비트 부동소수점(float) 형식으로 설정합니다. 대부분의 딥러닝 모델은 연산 속도를 위해 float 타입을 사용합니다.
- X_train과 Y_train은 각각 입력 데이터와 **타겟 값(레이블)**을 텐서로 변환한 것입니다.
# DNN 학습
begin = time()
print("{0:=^20}".format('DNN 학습 시작'))
for epoch in range(MY_EPOCH):
output = model(X_train)
# 출력값 차원을 (212,1)에서 (212,)로 조정
output = torch.squeeze(output)
# 손실값 계산
loss = criterion(output, Y_train)
# 손실값 출력
if(epoch % 10 == 0):
print('Epoch: {:3},'.format(epoch),
'Loss: {:.3f}'.format(loss.item()))
# 역전파 알고리즘으로 가중치 보정
optimizer.zero_grad()
loss.backward()
optimizer.step()
end = time()
print('최종 학습 시간: {:.1f}초'.format(end - begin))이 부분의 코드는 DNN(Deep Neural Network)의 학습 과정을 다룹니다.
학습 과정에서 에포크(Epoch)마다 모델의 출력값 계산, 손실값 계산, 역전파 알고리즘을 통한 가중치 보정을 수행합니다. 이 과정을 설명하면서 각 코드의 역할을 단계별로 알아보겠습니다.
학습 시작 시간 기록
begin = time()time(): 학습을 시작하는 시점의 시간을 기록하여 학습이 끝난 후 총 학습 시간을 계산하는 데 사용됩니다.
에포크 반복문 (Epoch Loop)
for epoch in range(MY_EPOCH):for epoch in range(MY_EPOCH): 지정된 에포크 수(MY_EPOCH)만큼 학습을 반복합니다. 여기서는 1000번의 에포크를 반복합니다.- 에포크(Epoch): 모델이 전체 데이터셋을 한 번 학습하는 과정을 1 에포크라고 합니다. 학습이 한 번으로 끝나지 않고 여러 번 반복됨으로써 모델이 점차적으로 학습됩니다.
모델 출력값 계산
output = model(X_train)model(X_train): 학습 데이터X_train을 신경망에 입력하여 모델의 예측값(output)을 계산합니다. 이는 각 에포크마다 모델이 학습 데이터에 대해 현재까지 학습한 가중치를 기반으로 예측을 수행하는 단계입니다.
출력값 차원 조정
output = torch.squeeze(output)torch.squeeze(output): 신경망의 출력값은(N, 1)처럼 2차원 형태로 나오는데, 이를(N,)으로 차원을 줄이는 작업을 수행합니다. 즉,(212, 1)형태를(212,)형태로 변환하여 계산을 더 효율적으로 수행할 수 있게 합니다.squeeze()는 차원이 1인 축을 제거하는 역할을 합니다.
손실값 계산
loss = criterion(output, Y_train)criterion(output, Y_train): 손실 함수(criterion)를 통해 모델이 예측한 값(output)과 실제 값(Y_train) 간의 오차(손실)를 계산합니다. 이 코드에서는 MSELoss(평균 제곱 오차)를 사용하므로, 예측값과 실제 값의 차이를 제곱하여 평균낸 값을 반환합니다.- 손실값(loss): 모델이 얼마나 잘못 예측했는지를 나타내는 값이며, 이 값을 최소화하는 것이 학습의 목표입니다.
손실값 출력 (매 10번째 에포크마다)
if(epoch % 10 == 0):
print('Epoch: {:3},'.format(epoch), 'Loss: {:.3f}'.format(loss.item()))if (epoch % 10 == 0): 에포크가 10의 배수일 때마다 손실값을 출력합니다. 학습이 잘 되고 있는지 확인할 수 있도록 일정 주기마다 손실값을 출력하는 것이 유용합니다.loss.item(): 텐서 형태의 손실값을 파이썬 스칼라 값으로 변환하여 출력합니다.- 출력 형식: 에포크 번호와 손실값을 출력합니다. 예를 들어,
Epoch: 10, Loss: 0.123처럼 에포크 번호와 그에 따른 손실값이 출력됩니다.
- 출력 형식: 에포크 번호와 손실값을 출력합니다. 예를 들어,
역전파 알고리즘으로 가중치 보정
optimizer.zero_grad()
loss.backward()
optimizer.step()optimizer.zero_grad(): 이전 에포크에서 계산된 기울기(Gradient)를 초기화합니다. PyTorch는 기울기를 누적하는 방식이므로, 매 에포크마다 기울기를 초기화해야 새로운 기울기를 정확히 계산할 수 있습니다.loss.backward(): 역전파(Backpropagation) 알고리즘을 사용해 모델의 손실값에 대한 기울기를 계산합니다. 이 기울기를 이용해 각 파라미터가 얼마나 업데이트되어야 할지를 결정합니다.- 역전파는 손실값을 최소화하기 위해 각 파라미터(가중치, 편향)가 어떻게 조정되어야 할지를 계산하는 과정입니다.
optimizer.step(): 앞서 계산된 기울기를 바탕으로 모델의 파라미터(가중치)를 업데이트합니다. 이 단계에서 가중치가 조정되어 모델이 더 정확한 예측을 하도록 학습됩니다.
학습 완료 후 시간 출력
end = time()
print('최종 학습 시간: {:.1f}초'.format(end - begin))time(): 학습이 끝난 시점의 시간을 기록합니다.end - begin: 학습 시작 시간(begin)과 종료 시간(end)의 차이를 계산하여, 총 학습 시간을 출력합니다.


모델 평가
X_test = torch.tensor(X_test.values).float() # 테스트 데이터를 Tensor로 변환
with torch.no_grad(): # 평가 단계에서는 기울기 계산을 하지 않음
pred = model(X_test) # 모델로 예측 수행
pred = pred.numpy() # 텐서를 numpy 배열로 변환
pred = (pred > 0.5) # 0.5를 기준으로 이진 분류
f1 = f1_score(Y_test, pred) # F1 점수 계산
print("최종 정확도 (F1 점수): {:.3f}".format(f1))
테스트 데이터를 torch.no_grad()로 예측한 후,
Sigmoid 함수 결과가 0.5보다 크면 True(1), 작으면 False(0)로 변환하여 이진 분류합니다.
최종적으로 F1 점수로 모델의 성능을 평가합니다.
더보기
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from time import time
import torch
from torch import nn
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.metrics import f1_score
#하이퍼 파라미터
INPUT_DIM = 13
MY_HIDDEN = 1000
MY_EPOCH = 1000
# 추가 옵션
pd.set_option('display.max_columns', None) #출력할 컬럼수를 조정하지 않겠다.
torch.manual_seed(111)
import numpy as np
np.random.seed(111)
# 데이터 준비
# https://www.kaggle.com/code/mragpavank/heart-disease-uci/input
raw = pd.read_csv('./dnn/heart.csv')
# pandas의 dataframe을 섞는다.
# raw = raw.sample(frac=1)
# pandas의 dataframe을 섞은 후 인덱스 재조정.
raw = raw.sample(frac=1).reset_index(drop=True)
# 303개의 행중에서 100개만 가져 올 때 =>
# 100개의 행에는 target이 True인것만 있음 그래서, 위에 처럼 섞어야 함.
# raw.drop(raw.index[100:], inplace=True)
raw = raw.drop(raw.index[100:])
# 데이터 원본 출력, 전체 행의 수 : 303개, 전체 열의 수 : 14(target 포함)
print('원본 데이터 샘플 10개')
print(raw.head(10))
print('원본 데이터 통계')
print(raw.describe())
# 데이터를 입력과 출력으로 분리
X_data = raw.drop('target', axis=1)
# 전처리 작업 : 훈련 전 이상 데이터를 줄여서 적합하고 유의미한 자료로 만드는 과정
# INPUT_DIM의 값도 조정해야 함. 예) 13 -> 11
# X_data.drop('fbs', axis=1, inplace=True)
# X_data.drop('chol', axis=1, inplace=True)
Y_data = raw['target']
names = X_data.columns
print(names)
# 데이터를 train(훈련용, 학습용)과 test(평가용)으로 분리
X_train, X_test, Y_train, Y_test = \
train_test_split(X_data, Y_data, test_size=0.3)
# shape 출력
print('학습용 입력 데이터 shape:', X_train.shape)
print('학습용 출력 데이터 shape:', Y_train.shape)
print('평가용 입력 데이터 shape:', X_test.shape)
print('평가용 출력 데이터 shape:', Y_test.shape)
# 입력 데이터 z-점수 정규화
# 결과가 numpy의 n-차원 행렬 형식
scaler = StandardScaler() # z-점수 정규화
# scaler = MinMaxScaler() # 최소-최대 정규화
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)
# print('Before type:', type(X_train))
# numpy에서 pandas 로 변경
# header 정보 복구 필요
X_train = pd.DataFrame(X_train, columns=names)
X_test = pd.DataFrame(X_test, columns=names)
# print('After type:', type(X_train))
print('z-점수 정규화 된 학습용 데이터 샘플 10개')
print(X_train.head(10))
print('z-점수 정규화된 데이터의 통계 출력')
print(X_train.describe())
sns.set(font_scale=2)
sns.boxplot(data=X_train, palette="colorblind")
# plt.show()
# 인공 신경망 구현
# ▪ 파이토치 DNN을 Sequential 모델로 구현
# ▪ Linear : 입력층 + 은닉층 1
# ▪ Tanh 활성화
# ▪ Linear : 은닉층 1 + 은닉층 2
# ▪ Tanh 활성화
# ▪ Linear : 은닉층 2 + 출력층
# ▪ Sigmoid로 나옴
print("{0:=^20}".format('인공 신경망 구현'))
model = nn.Sequential(
nn.Linear(INPUT_DIM, MY_HIDDEN),
nn.Tanh(),
nn.Linear(MY_HIDDEN, MY_HIDDEN),
nn.Tanh(),
nn.Linear(MY_HIDDEN, 1),
# nn.Linear(MY_HIDDEN, 5000),
# nn.Tanh(),
# nn.Linear(5000, 1),
nn.Sigmoid()
)
print('DNN 요약')
print(model)
# numel() : torch Tensor의 크기 구함
# p는 가중치라고 보는게 맞음
total = sum(p.numel() for p in model.parameters())
print('총 파라미터 수 : {:,}'.format(total))
print("{0:=^20}".format('인공 신경망 학습'))
# 최적 함수와 손실 함수 지정
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# RMSprop은 최적화 도중, 학습율을 상황에 맞게 조절하는 기술을 SGD에 추가, SGD보다 진화된 알고리즘
# optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# 학습용 데이터 전환
# pandas dataframe에서 python tensor로 변환
X_train = torch.tensor(X_train.values).float()
Y_train = torch.tensor(Y_train.values).float()
# DNN 학습
begin = time()
print("{0:=^20}".format('DNN 학습 시작'))
for epoch in range(MY_EPOCH):
output = model(X_train)
# 출력값 차원을 (212,1)에서 (212,)로 조정
output = torch.squeeze(output)
# 손실값 계산
loss = criterion(output, Y_train)
# 손실값 출력
if(epoch % 10 == 0):
print('Epoch: {:3},'.format(epoch),
'Loss: {:.3f}'.format(loss.item()))
# 역전파 알고리즘으로 가중치 보정
optimizer.zero_grad()
loss.backward()
optimizer.step()
end = time()
print('최종 학습 시간: {:.1f}초'.format(end - begin))
print("{0:=^20}".format('인공 신경망 평가'))
# 평가 데이터 타입 변환
X_test = torch.tensor(X_test.values).float()
# DNN으로 추축, 가중치 관련 계산 불필요
with torch.no_grad():
pred = model(X_test)
# print('pred:', pred)
pred = pred.numpy() #추축 결과 tensor타입을 numpy로 전환
pred =(pred > 0.5)
print(pred.flatten())
f1 = f1_score(Y_test, pred)
print("최종 정확도 (F1 점수): {:.3f}".format(f1))